
MCML: Metacontent, information access, and the consumer Internet
In retrospect...
This paper represents another Don Norman-inspired "think big thoughts about Apple's future" project. There are two things of interest in it, which are only slightly related to the other:
(1) There should be a way to attach semantics to web content, such that the code for a web page might represent something about what it means. I was working on this about the same time that R. V. Guha was working on MCF on another floor at Apple. MCF, and later RDF, and more generally XML, put these representations in separate documents that lived in parallel with the HTML, while I was interested in how the semantic representation might be captured within the HTML code. I learned a couple of things from this aspect of the project, including (a) it's really hard to implement new standards (still true) and (b) it's really hard to connect semantics to web content (still true).
(2) There is value in making it easy for people to put information about themselves on the Internet, and to provide access to that information either to the public at large or to a specific set of their friends or family members. A similar argument holds for providing communication support between these informal groups of people. No, I'm not claiming that I invented Facebook in 1996. But, still, the pieces were there....
1. The questionable(?) future of the Web.
1995 was the year of the Internet and the year of the Web, and for good reason. The widespread adoption of HTML and HTTP as standards, the creation of huge amounts of content around those standards, and the availability of term-based indexes to these documents together led to a fundamentally new computing experience, one that is of special importance to Apple because of its foundation in open standards. Nevertheless, there is reason for concern about the broader adequacy of this model, both in its continued ability to support the huge amounts of information being directed toward it and in its applicability to the wide range of tasks that it might ultimately address. The fundamental problem here is that, although we now have desktop access to tens of millions of documents, we lack a systematic way of referring to and accessing the information inside those documents — the price of a product in a catalog, or the PIM-like information found on a home page. Without such a method, our search capabilities are limited to general, document-level search techniques that risk being overwhelmed by the sheer mass of information entering the Internet; similarly, we can't directly integrate that information into our desktop computing environments. The result is that an incredibly valuable resource is not being used as fully as it might be.
This paper describes several aspects of this general problem, and outlines an equally-general solution to them. The basic claim is that significant improvements in the manipulation of HTML-based information can come from introducing metacontent — machine-interpretable descriptions of the content of a page — into the HTML representation of Web pages. These descriptions, implemented as an extension to the HTML standard, make possible broad new classes of software and services. and offer significant business opportunities to those able to control and exploit that information.
Existing models of metacontent.
There are a few examples of metacontent in the Web, but not many. Hierarchies such as Yahoo and Excite offer one view of metacontent; these are hand-crafted classifications of Web pages into a topic hierarchy, viewable with a Web browser but not particularly machine-accesible. A Web crawler could, of course, walk over this hierarchy and reconstitute it in an appropriate form; this is the basis for HotSauce. This makes the hierarchy available to applications, but it does not provide access to the finer-grained content of these pages; that still requires human- or machine-based analysis of the pages themselves. One can imagine analysis engines that are tuned for documents of certain forms and contents, but general machine-based understanding of the structure of Web (or other) documents reduces to the knowledge acquisition problem of artificial intelligence. Some knowledge acquisition research programs have begun to address Web-based content (Footnote 1); while it's great to see research in this area, it's at best a very challenging task and, at worst, more tilting-at-windmills AI research. A final area of work on metacontent to note is the work on MCF underway here at Apple — building a representational interlingua for the content of databases and other Web sources and a retrieval tool for automatically constructing queries that join multiple databases. Here, database authors have the responsibility of writing a translator between their database's format and the interlingua, a doable, one-time task. This bridges the gap between databases and Web access techniques, but a similar bridge between those techniques and arbitrary Web pages is another matter.
2. MCML: HTML extended by a metacontent markup language.
What these techniques have in common is the approach of building a metacontent structure that parallels and points into the Web information, thereby attributing meaning to them. The alternative to be discussed here is to embed the metacontent into the page, as an extension to the HTML standard. This standard would encompass three things: a syntactic extension to HTML for expressing the metacontent, a semantics for the metacontent, and an ontology of the objects to be described in this system.
<HTML> <HEAD> <TITLE>ATG Information Access</TITLE> <META pageClass=ResearchProject> </HEAD> <IMG SRC="InfoAccessLogo2.GIF" alt="Information Access"> <hr> <h2>What We Do</h2> The <A attr=parent_organization>ATG</A> <A attr=name>Information Access</A> research group (formerly known as InfoTech) includes: <ul><li> <A href="/documents/personalpages/Dan_Rose/DanRose.html", attr=managerOf>Dan Rose</a>, Manager<li> <A href="/documents/personalpages/Doug_Cutting/DRC.html", attr=memberOf>Doug Cutting</a><li> <A href="/documents/personalpages/Jeremy_Bornstein/home.html", attr=memberOf>Jeremy Bornstein</a> <li>John Hatton (intern) </ul> We're interested in how people interact with (primarily textual) information — how they find it, organize it, navigate it, etc. [...]
This paper proposes such a standard: MCML (MetaContent Markup Language). It assumes a simple frame-like ontology of objects with attributes and values, most likely with inheritance from parent to child objects. The representational scheme then maps a page into that ontology, and maps parts of the page's content to the attributes associated with the page's class. Syntactically, this is done through an extension to standard HTML. Consider the following pages, taken and adapted from the ATG Web server; MCML extensions to HTML are shown in boldface.
In Figure 1, the page-level pageclass tag identifies where this page falls in the ontology; here, an instance of ResearchProject. Research projects then have certain attributes, identified in the page by attr tags: a name, a parent organization, a manager, and some members. Attributes are marked in the body of the text through the extension of the HTML anchor provision, and can be filled by either an explicit value (e.g., the name of the project) or a link to another page (e.g., the manager of the project). Note that all these annotations are invisible when viewed in Web browsers, since, as a rule, browsers simply ignore HTML tags that they don't know how to interpret.
Similarly, Figure 2 shows a page of pageclass Person, with such attributes as name, address, and email address.
Two important things should be noted about these examples. First, the specific syntax shown here is not particularly important, nor are the details of the class hierarchy and the corresponding attributes. There is plenty of room for debate, refinement, and prototyping here, and some early but relevant standards proposals for metacontent syntax are beginning to appear in the Web community. (Footnote 2) These details should be easy to resolve; what is really important here is the demonstration that this information can be represented in general conformity with HTML notation, and that the task facing the author of such a page is relatively simple. This lets us ride the HTML/Web wave in terms of both infrastructure (i.e., using HTTP as the transport mechanism for the metacontent) and mindset — "You're still building Web pages; you're just adding a few more tags to your content". Tool support would ease the process further; one can imagine a PageMill-like tool that allows an author to choose the class of which this page is an instance, and then allow parts of the page's content to be tagged via the same sort of highlighting and menu selection techniques that are used to specify fonts and character styles. Structure detectors might also be used to pick out pieces of content that would be especially likely to be marked, such as e-mail addresses. home page URLs, and phone numbers.
<HTML> <Title>Dan Rose</Title> <META pageClass=Person> <BODY> <H1><A attr=Name>Dan Rose</A></H1> <IMG ALIGN = TOP SRC = "Snowdog.gif" alt = "[A Picture of Dan]"><p> <b>E-Mail:</b> <a href="mailto: rose@apple.com",attr=EmailAddress>rose@apple.com</a> <p>Manager, <a href="/documents/areas/InfoAccess/InfoAccess.html"> ATG Information Access Group</a><br> <a href="https://www.apple.com", attr=Business>Apple Computer, Inc.</a><br> <A attr=Address>One Infinite Loop, MS 301-4A</A><br> <a href="https://www.mvhs.edu/cupertino/", attr=City>Cupertino</a>, <A attr=State>CA</A> <A attr=Zip>95014</A><p> <hr> <h2>Background</h2> <hr> <h3>Origins</h3> I grew up in Northampton, Massachusetts, a smallish town in the Western part of the state (look for 13 on <a href="https://www-astro.phast.umass.edu/misc/mass.html">this map</a>). [...]
Second, what is being captured here is less a representation of the "meaning" of the page in a serious AI sense than a gross classification of the page into an ontology, and the mapping of specific bits of the page's content to attributes in the ontology. The goal here is simply to make enough of a page's content computationally accessible that we open the door to information access and Internet-desktop integration services that are significantly more powerful than those currently available.
Where does the standard come from?
In this model, some standards organization would define the syntax and semantics of the MCML extension and the base content of the ontology. Apple's goal should be for MCML to exist as an open standard under the sponsorship of the WWW Consortium or other appropriate standards groups, but controlled by Apple in a pragmatic sense, just as Netscape pragmatically controls the broad HTML standard. Like Netscape, we control the standard by developing a market-dominating set of products and services that exploit MCML and, in particular, products and services that implement and make use of "proposed enhancements to the standard". This keeps our products and services ahead of the competition, and insures that the integration between Web metacontent and MacOS is superior to competing operating systems. The result is a set of superior products and services keep us in control of the standard, which, circularly, puts us in a better position to produce superior products and services.
This discussion is admittedly a little glib; the real work in defining a standard lies not in writing the specification, but in demonstrating the value of the standard and getting it widely adopted by its target community. Hence, we should consider a few ways in which MCML could extend our current model of the Internet.
3. Opportunity 1: Strategy-based information retrieval.
The term-based model of searching for documents, made popular through Lycos, InfoSeek, and other Web-based search engines, is at risk. There is, or soon will be, so much information on the Web that a few significant words can no longer guarantee that valuable information can be discriminated from irrelevant chaff. In any case, a gap exists between the services offered by these search techniques and the real tasks for which they're being used. If you're searching for people doing research on information access, asking Lycos (Footnote 3) about "information access" will return a hodgepodge of pages that is a good starting point, but a long way from your real goal. That list of people will be found only after you manually search the information spaces around those pages. This is inevitable, given the current search framework: you can't get pointers to people, since the indexing procedure and the search engines have no principled way to tell which pages describe people, or research projects, or anything else. Web pages are not database records, but simply bags of words, with no further meaning or structure.
This limited means of accessing Web-based information has also stood in the way of real Web commerce, especially the much-anticipated notion of "shopping agents". Independent of the sociological questions about the exact role that agents and the Web might play in shopping — there's a big difference between shopping and ordering! — it's clear that an agent can't find a good price on something if it doesn't know where it can find the things it's looking for, how much they cost, or how to order them once they've been found. These are all very specific pieces of information, and unless they're explicitly captured in some machine-accessible format, it's hard to see how Internet commerce can proceed. General Magic and AT&T built a promising distributed computing infrastructure with TeleScript, but they left out the layer of information that would have tied this infrastructure into their customers' buying and search needs; in retrospect, it shouldn't be surprising that they've failed to make Web-based commerce real.
How does MCML help?
MCML changes this picture in two significant ways:
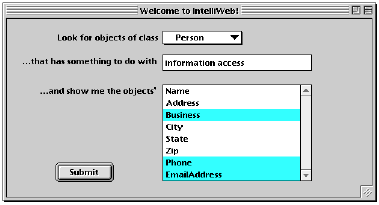
- Ontology-based queries and query tools. By referring to the ontology underlying MCML, query tools can allow users to build a richer description of the information they're looking for. The simple interface to a Lycos search engine — a text field — can be replaced by a more interactive system that, through reference to the ontology, allows users to specify the classes and attributes of objects they're searching for (Figure 3). As a result, the work of the query system can be more precise, and come closer to meeting the real needs of the user. Given a search like that for the phone numbers of people working on information access, the query system can search for pages related to "information access", pick out the ones that are instances of People (or a sub-class of People), go into those pages to retrieve the particular bits of information specified in the query, and create a page that contains exactly the information requested by the user.
- More sophisticated search strategies. An MCML-based query system can make use of the ontology as part of its search process. Staying with the "information access" example for a moment, a query system might extend the search strategy above to consider other kinds of related objects. For instance, if a page of class ResearchProject is found by Lycos, the query system might look at its managerOf and memberOf attributes: references to people in those attributes would surely be people involved with information access. Hence, the MCML ontology can serve as the basis for doing highly-focused searches around pages identified by more general, term-based searches, and offer considerably more powerful responses to user queries.
A demonstration version of this system exists. A partial copy of the ATG internal web site was created, and relevant pages were annotated with the prototype MCML format shown in Figures 1 and 2. A CGI script was then written to implement some search strategies like those described above. In particular, the "search for people who..." strategy was implemented, using V-Twin as the search engine that provides the term-based search on which the MCML search was based. (Footnote 4) The query tool shown in Figure 3 was used to generate and send queries to this query system, which uses Netscape to display the results of the search.
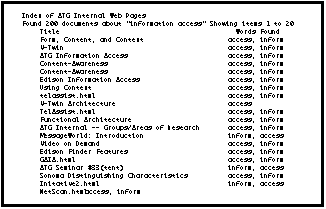
Figure 4: Results of the V-Twin search for "information access" (Top 20 hits)
The differences between the basic V-Twin and the enhanced MCML searches are instructive. Figure 4 shows the results of doing a V-Twin search for "information access" on the ATG internal web site; Figure 5 shows the results of the MCML search.
There are two things to note in this comparison. First, the results of the MCML search correspond directly to the query; they are are much more concise and specific than V-Twin's. Only those pages matching the query are shown (although the other pages found by V-Twin remain accessible through the "These links might also be relevant" section), and the attributes requested in the query are returned as a direct result of the query, with no further search required. Second, the MCML search found pages not found by V-Twin; in fact, none of the people found by the MCML search appear in the first listing of 20 pages found by V-Twin. (The Dan Rose page shows up at #44, and the Doug Cutting page at #45.) This greater search success comes from the two-stage search process made possible by MCML: These pages were found not because their contents emphasize information access — indeed, the pages for Strong and Miller don't mention information access at all — but because they are pointed to by memberOf and managerOf attributes in ResearchProject pages found by V-Twin. The intent of this comparison is not to criticize V-Twin, but to note how its techniques complement those of MCML, and are ultimately synergistic with it. The MCML search is utterly dependent upon V-Twin to cast a wide net through the information space and find likely starting points, from which MCML techniques can extend and refine the search.
Second, note how MCML opens up the information access services market. That market is currently quite limited, in terms of the ability of different search sites to discriminate their services. The user interaction models of these services are basically the same — the user types a list of terms into a text field. With MCML, the richer user interaction space enabled by search for particular objects and attributes means that search sites could compete on who offers the most direct and most powerful interfaces to their information — perhaps a form-based interface like that in Figure 3; perhaps a graphical browser like Vasa; perhaps a constrained natural language system.

Similarly, the search technologies offered by Lycos and its competitors are basically the same — some sort of vector search analysis, often augmented with "find related pages" options. While this technology is still central to the MCML approach, it is easy to imagine search sites competing on who can offer the most clever MCML-based search strategies. In the example above, the search strategy making use of the project information leads to much better results than one using only person information, and so should draw more users; still other strategies might be designed by other vendors that could lead to still faster or more complete results. The point is that these strategies are independent of the information space; as such, they would be proprietary assets of the vendor offering them. The result, we hope, is a large number of vendors furiously competing around their use of an Apple-controlled technology, and the establishment of Apple as a central, critical player in this area.
4. Opportunity 2: Internet-desktop integration.
The Web is a compelling place to visit, but it's very difficult to live there. That is, there is little if any integration between Web-based information and the documents and applications around which our desktop computing activity is based. Currently, the Web is a place that we go to with Web browsers, not with a full set of computational tools. A huge opportunity is being missed here. The power of HTML expands considerably if we choose to think of it as a general way of representing information, one for which an inter-machine transfer protocol happens to have been defined and distributed. There's nothing wrong with people looking at HTML pages with Web browsers, but we should also consider the value that could come from spreadsheets, address books, calendars, and many other sorts of programs looking at the information in those same HTML pages. Of course, these programs lack our human ability to look at the mass of text and graphics on a page and pick out the information relevant to our task, and, as noted earlier, they're not likely to gain that ability any time soon. If we want to bridge the gap between the Web and our personal computing worlds, we need to think about how the structure of the information in those pages might be captured and represented, and made accessible to a wide variety of traditional applications. This is a problem that MCML is well-suited to address.
Consider the problem of keeping your address book up to date. The current class of PIMs largely solves the problem of organizing that information and making it generally available in your desktop world, but it misses the broader fact that this information changes frequently and unpredictably. Home pages offer an easy way to publish information about yourself within the Internet, but there's no direct way to integrate this information into the desktop world of the PIM; the best I can do is manually copy the information from the web into my PIM, after I've discovered that my information is out of date.
MCML-based web pages can solve this problem. We can define a small ontology for personal information, with such attributes as name, address, workPhone, and emailAddress, which can be used to annotate the information in a home page (Figure 6). This provides the foundation for Web-based extensions to PIMs, such as:
- If I want to add someone to my PIM, all I need is the URL for their home page. The MCML-enabled PIM can retrieve the page, extract the tagged information, and build an entry for this person. It can also create a permanent connection between the home page and the corresponding entry in the PIM.
- This connection can be used to keep the PIM's information constantly up to date. At some appropriate and user-defined interval (once a month? on demand? whenever an entry is opened?) the PIM can check those connections, note any changes, and update itself automatically.
- To reverse perspectives: When my phone number changes, all I have to do is change it on my home page, and rely on the Web and MCML-complient PIMs to propagate that information out to the people who are interested in it.
<HTML>
<HEAD>
<TITLE>Default.html</TITLE>
<META pageClass=Person>
</HEAD>
<BODY BACKGROUND="PieceOfWater.GIF">
<H1><A attr=Name>Jim Miller</A>
<IMG SRC="Jim.GIF" WIDTH="107" HEIGHT="138" NATURALSIZEFLAG="0"
ALIGN="MIDDLE"></H1>
e-mail: <A HREF="mailto:jmiller@apple.com",
attr=EmailAddress>jmiller@apple.com</A><BR>
work phone: <A attr=workPhone>408-862-5546</A><BR>
home phone: <A attr=homePhone>415-967-2102</A><BR>
[...]
A prototype of this system exists, using Now Contact and some AppleScript as the MCML-enhanced PIM. Of course, the overall approach being demonstrated here is much more general than this example of address book management; it applies to any situation in which the information in a web page can be mapped into the domain of a desktop application.
An important — perhaps the most important — part of this approach is its reliance upon open standards for the representation and access of the information: Any application on any platform can play, as long as it can interpret the publicly-defined MCML extensions to HTML. This is not the only way in which this scheme could be implemented; there are all sorts of ways in which competing application/OS vendors (bluntly speaking, Microsoft) could implement proprietary versions of same approach. However, it's clearly in Apple's interest to keep the protocols open and platform-irrelevant, to insure that Mac and Windows users are on equal footing for the creation and consumption of this information. As noted before, it will again be important for us to drive the standard forward and offer leading-edge services and products that exploit this standard; in this case, as part of the desktop environment. But this is something that our ownership of the MacOS platform enables us to do; the more that this standard is tied into the desktop environment, the harder it becomes for an independent party (bluntly speaking, Netscape) to do. The real challenge would be to keep control of the standard out of the hands of Microsoft, who, because of the openness of the standard, could incorporate it into Windows and play a competing standards game. Of course, we should do all we can to get Windows applications to make use of MCML, since these applications will then be creating content to which Macs will have complete access. But it may be tricky for Apple to evangelize the standard into the Windows community while, at the same time, maintaining control of the standard.
5. Standards adoption: How to win friends and influence people with MCML.
Once again: the opportunity presented by MCML is to allow Apple to define and exploit a standard layer in the Internet. Success here is a three-fold task: we must be sure that the layer is technically sound (so that developers find it worth adopting), we must work politically to establish the standard in the developer/user community (so that developers actually adopt it), and we must exploit our control of the standard to produce successful products in both Internet and product spaces (so that Apple makes money).
There are surely technical issues with MCML that need to be addressed. The language has intentionally been kept simple, in the interests of easing adoption by developers. Still, both the syntax and semantics of the language need review to confirm that it's both usable and expressive enough to deliver the intended value to developers. We need to think through the kinds of APIs that would let developers access MCML-based information, and make them available cross-platform. Direct access to MCML content in arbitrary web pages is essential; we should also explore how the MCML type and attribute information of a page can be cached and indexed so that pages wouldn't have to be physically accessed in the course of a search. We need to think through how the set of officially-supported ontologies are defined and maintained, and how that set of ontologies can be extended in both breadth (whole new concepts) and depth (more specific concepts), both as a formal part of the standards process and as an informal matter among people who choose to agree among themselves to work with a certain ontology. There are indeed questions here, but the hope here is that the system, more or less as defined here, allows reasonable near-term solutions to those questions, while also permitting more sophisticated solutions in the long-term, as our theoretical and practical understandings of MCML evolve.
While the political adoption of MCML will need to be fought on several fronts, the ultimate question is how to get the MCML ball rolling, so that it becomes a ubiquitous part of the Internet world, and developers build their applications and content around it in as matter-of-fact a way as current HTML developers work with tables. It seems clear that Apple can't do this by itself; we will have to partner. Some obvious partners would include:
- Netscape, as the dominant player in HTML standards. They have not yet shown interest in defining this sort of standard, and so, hopefully, should be enlisted. "Support" means that Netscape announces public support for the standard, and helps get the MCML ball rolling by building MCML tags into their web site content (e.g., building their product description pages around a product ontology that we might define together).
- Netscape, Adobe, Claris, and other developers of HTML tools. These companies' tools should make it easy for content developers to add MCML tags to their pages through typical, Mac-like methods (e.g., assigning an ontology to a page by selecting it from a menu or other interface device, or highlighting regions of text and selecting the desired ontology attributes from a menu).
- Yahoo, Lycos, and/or other search and indexing services. Their content should incorporate MCML attributes, and their search engines should offer some sort of query techniques that take advantage of MCML's capabilities (cf. Figure 3).
While partnerships like these would be critical to the success of MCML, it's probably inevitable that the ultimate responsibility for the success or failure of MCML will lie with Apple. We can drive these partnerships and offer the same kinds of support, but if we don't make a strong commitment to the approach and find ways to utilize it that offer unusually-strong benefits, it's doubtful that anyone else will. Of course, it's also through demonstrating such benefits that we drive the creation of lots of MCML content, and get into the desired position from where we are unfairly exploiting the standard, using that control to build products with capabilities well beyond those of our competitors, and making lots of money for Apple. The rest of this paper describes one such system, which could open the door to the much wider use of Internet-based products in the home/consumer market. It would make the Internet broadly successful by making much of it disappear...
6. Opportunity 3: The invisible Internet and the Apple Family.
Let's pull this discussion up a level of abstraction or two, and ask the basic question: What is Apple's Internet user experience to be?
Some answers to this question are all but given. We should surely aim to be the best possible platform for web browsing. This means making sure that world-class web browsers, helpers, and plug-ins are available on MacOS, and we should work to insure a continued advantage in system setup, so that it's easier to get a Mac on the web than any other machine. However, it's hard to see that simply doing this will get us a huge market advantage over other platforms. While Cyberdog and OpenDoc offer us some hope here, we're still fighting a numerical disadvantage in platform market share, despite our relatively stronger position among on-line users. Correspondingly, many developers of helper apps and plug-ins build for Windows first and maybe only, and are further designing around an architecture controlled by Netscape. Easy setup and the availability of world-class tools are essentials for us to be a competitor, but they're not enough to let us win.
We should also tie the Web into the rest of the Mac user experience as seamlessly as possible. Plans for this incorporating Internet-related capabilities into Maxwell are underway; perhaps Find File could allow users to launch a web search as easily as a file system search, or Apple Guide could allow users to jump from an assistance interview into a live "assistance center" chat room. There are innovative and valuable possibilities here; others are again a matter of keeping ourselves competitive with other platforms.
So far in these examples, the Web and its usual tools are still present in their usual forms; the question is how users access it. There is more we can do here; we can push the integration of the Internet and the Mac even further, to where it's the basis for how people share information critical to their real tasks. This is what the Mac did a long time ago — let people focus on their tasks and let the system worry about the details — and it's time to do it again. The previous discussion of MCML gives some hints about what might be possible; consider the following scenario of how the Internet could be brought fully into the user experience without a URL ever showing its face.
A scenario: The Apple Family.
This scenario describes Apple Family: a consumer-oriented computing environment whose primary function is information management and communication, with a special focus on providing support for informal communities. The Internet is key to all of this, but as an invisible supporting infrastructure. Yes, there's a Web browser in the system somewhere and you can surf if you want to, but it's not a central part of the experience; it might even be seen as a rather geeky thing to do.
What's in the system?
The main parts of Apple Family are:
- Some sort of computer, of course. This could be a traditional Mac or something even more consumerish. It could also be a variant on a Newton. The exact platform is irrelevant to the discussion that follows; the only thing that's significant is that there is a high-speed modem or other communications device built into or, at least, provided with the computer as an intrinsic part of the product.
- A free short-term (3 month?) "start-up" subscription to an Apple-based Internet service. This is free as far as the user is concerned, but some part of the cost of the product goes to cover the cost of this service. More on the business model will come later; for now, simply note that this would be a full-fledged Internet service, and so would provide all the usual web, newsgroup, and e-mail services. However, its real purpose is to insure that the user is a member of ...
- The Apple Family. The user is registered on an Apple server, and, as such, is able to take advantage of a wide collection of services, tightly integrated with desktop applications that make it easy to interact with other individual and group members of Apple Family, as well as other users of the Internet. Much of what the user does with these applications and services will involve connections to the Internet, although the setting-up and use of those connections will often be completely invisible to the user.
Welcome to the Family.
The design center of Apple Family is a simple and direct interface to other people and organizations registered with the service, one that makes it very easy to communicate and share information with these people. This is made possible through a combination of applications — Apple-provided and third-party — and web-based services.
A particularly important service made available as part of the Family is the Family Registry: a searchable database of all Family members. This could be viewed as either a web resource or a system application; in either case, it should have much of the visual appearance of a phone book, and is meant to function in the same way: users can look through it in search of people or organizations they want to be able to communicate with. There is Internet technology underneath all of this, but it's well-hidden. Looking at someone's entry in the Registry amounts to looking at their home page, but I do this by clicking on their Registry entry that looks more like an entry in an address book than anything else, not by typing a URL into a Web browser. Similarly, e-mail messages can be sent, and phone calls can be made, by clicking or dragging a Registry entry in some appropriate way. Registry entries can also be dragged to a personal Address Book, where they can be saved for future, local use. In addition to individuals, the Family Registry would also contain listings for organizations: schools, government agencies, businesses, and other groups. The purpose is the same: to provide an electronic contact point for the group, around which Family services can be provided.
In addition to these formal organizations, the environment acknowledges that many social interactions involve groups of people that are personal, arbitrary and informal, and whose membership is dynamic, often lasting from a few weeks to a few months. Apple Family supports this fact through the concept of Circles of Friends: personally-defined groups of people you want to share information with. These might include your family, your immediate circle of friends, or your son's soccer team; they might also be defined around personal interest areas, such as hobbies, civic activities, or other general areas of interest. You define your circles of friends, and you can control who can be in them, by offering invitations or accepting requests. You can also choose to reveal different bits of information about yourself to different people, based on the circles they're members of. Overall, the various parts of the Family system make it exceptionally easy to communicate with these collections of people, and to share information among them. This is an important, and unique, service provided through the Apple server; it is what distinguishes it from just another Internet service. Note that there are really two services being offered here: the computational services underlying the Family system and its features, and an implicit, social guarantee by Apple that the Family information is correct and reliable. For the system to be successful, we must be able to guarantee to users that the system is trustworthy; that the information they put into the system is secure, and that Family members are indeed who they say they are.
The scenario continues with examples of the capabilities that grow out of these features; along the way, we'll see how MCML makes much of this possible.
Scene 1: Opening the box.
The only real setup that's needed is to plug in the power and communication cables. A series of introductory animations plays on first power-up, leading to a screen presenting a registration form, prompting you for typical address book information such as name, address, phone number, and so on. So far, things seem fairly typical.
Scene 2: System registration.
After filling out the registration form, you click on Register, which makes a connection to an Apple-based server. (Footnote 5) The information from the registration form not only registers the machine for the usual warranty and marketing purposes, but it also creates an MCML-based home page on the server for that user. In a real sense, both the machine and the user are being registered with Apple. Three things come out of this registration process:
- You get a traditional HTML home page on a publicly-accessble server: anyone can look it with a standard Web browser, and it looks reasonably nice. There's another tool around, perhaps Cyberdog-based, that can be used to make the page look nicer and to add information to it, but the default page is at least reasonable.
- You also get an e-mail address on the server as part of the deal. This is a standard Internet address, just like the address of your home page is a standard URL. However, this geekiness may often not matter, since there are much easier ways for other Family members to reach you.
- You are added to the Apple Family database, based on what you entered into the registration form: You're known to be a person with a certain name, address, phone number, and so on. The user is aware that this information is being collected for public view on the Web, in ways that they've specified; indeed, this self-presentation is one of the reasons that the user bought the system in the first place. As a result, it's no more controversial than the presence of your name, address, and phone number in the telephone book.
Scene 3: Registering yourself.
After being validated into the server, you start exploring the Registry. You find the entries for a few of your friends, and drag them into your personal address book. You also find the entries for your childrens' school, the local pizza place, and your son's soccer coach. Next, you create a Circle for your family, dragging the entries for your mother and sister from the registry to the circle. Your daughter at college isn't registered, but you can create a de facto entry for her by typing in her e-mail address, URL, and other contact information into an appropriate form.
Now, you look at the details of some of the items you've created in your address book. You click on the entry for the soccer coach, and his entry in the Registry opens up to show the information he's approved for general public viewing. Note that this is technically just browsing his home page, augmented by the filtering that shows you only the "general public" information. But that's old-fashioned Web thinking; here, you're just looking at an extended address book entry. In any case, one of the things that's visible to you is the Circle that he's created for the team members' families. You click on this entry, and ask to be added to that Circle; a confirmation will come via e-mail a day or so later, after he receives your request and makes sure that your son is really on the team. Similarly, you visit the school's entry, and register in the Circle for your kids' classes (which also enrolls you in the Circle for the school as a whole). Once you're added to these Circles, entries corresponding to them appear in your address book. In most cases, they can be "opened up " to show the people in them. These are stored locally, since you'll want to be able to compose e-mail off-line, and will want to use the address book as a phone dialer.
Finally, you enter the Communities section of the Registry. This contains listing of Circles that roughly correspond to Internet mailing lists. You pick a few, corresponding to your interests, and these are added to your address book for future mailing and browsing. Most of these are open to anyone, and so require no confirmation, but others have some notion of membership, possibly involving fees; this is negotiated separately between you and the Circle maintainer.
Scene 4: Circles, new events, and e-mail.
A second key application in the Family is a calendar that can be used to record personal events and, in some cases, send events to or receive events to Circle members. The overall behavior of automatic notification of events is very much like that of Now Up-To-Date; in fact, if you wanted to use a version of Now Up-To-Date as your calendar, you probably could. However, the representation of the events on the server and the management of them on the client end is based on Web formats and MCML.
The school has just announced its yearly fund-raiser, a pancake breakfast. Someone at the school built an announcement of the breakfast as part of the school's home page, and anyone looking at the school's page with a traditional web browser would see that page in the usual way. However, let's assume that the tool used to build this announcement offered MCML enhancements: the announcement is marked as some sort of event, which has a startTime, an endTime, a location, and so on. When I open my calendar, it checks with the server to see if any of the Circles I'm registered with have published any new events. The pancake breakfast is found in the school's Circle, and is entered into my calendar, perhaps with a notification to make sure I know about it. My calendar is also getting the schedule for the soccer team by virtue of my membership in the soccer Circle, and it's a good thing, too — I'm told that this Friday's game has been moved to 4:00, at the field across town. This is a problem, since I have a doctor's appointment at 3:45. I drag the icon for the soccer Circle to my e-mail tool, and send a message to the Circle to see if somebody can give him a ride. I'll check back later to see if I have any luck. Alternatively, since the membership of the Circle is visible to all the members of the Circle, someone could drag my entry in their view of the Circle to a Phone icon, and call me. Finally, I notice that I mis-typed my home phone number in my entry in the Family Registry, so I correct it. If somebody tries to call me via the Registry entry, the update will propagate back to their address book, and the call will be made to the correct number.
Scene 5: Internet search and action.
My daughter's 16th birthday is coming up, and I have to find some sort of car for her to drive. The Mercury News classifieds are accessible through the Internet, so I decide to see sorts of used cars are available. I get a piece of Classifieds stationery from the Mercury News's entry in my address book (that is, from their home page), which gives me a form that I can fill out as the basis of a search of the classifieds. This form is the front end to an MCML-based tool that lets me choose the kind of thing I'm looking for and specify some of its attributes; in this case, the make, year, features, and an estimated price of a used car. When I submit the form, an MCML query is generated and sent to the Mercury News's server, and a list of matching cars is returned. I get what I'm looking for, and am happy; the Merc is also happy, since their customers are generally more able to find what they're looking for, something that they regularly mention in their advertising and their marketing to display and classified advertisers. They've also been able to replace the old database system that had supported their Classified system with their regular web server and some MCML annotation of the Classifieds pages: they've replaced three separate systems with a single set of MCML-based Classifieds files, which can be used to generate the listings that are printed in the paper, the browsable listings on the web, and the database-equivalent that is searched by their stationery tool and other, more general web techniques.
The scenario: Closing thoughts.
The problem with scenarios is that they often generate as many questions as answers, and this scenario is no exception. In particular:
- Could Apple Family be sold as an after-market product to current Mac users? Sure; all that's important is that the user have a Mac (Footnote 6) and a reasonable modem or other communications connection.
- Are we really talking about not just starting an Internet service business, but giving away Internet access? Well, yes and no. The "giveaway" notion is something of a red herring, since there's an assumption here of a certain price premium for the overall product to cover some or all of the cost of the service for the introductory period, and the "giveaway" would be at least partly countered by revenue coming in from the continued subscription to the service and other service-related revenue sources (e.g., advertising or commissions from commercially-oriented Circles). Ultimately, it's clear that a serious product exploration would require a carefully defined business model.
- Questions of exactly who owns and runs these servers (Apple? America Online? AT&T? a consortium of local ISPs? Individuals or organizations to whom we sell servers and software?) and how the servers fit together into a smoothly-running service-providing environment are important, and need to be thought through. However, the key point for right now is that these services be available from the very beginning, and that users are able to hook into them with zero effort. Apple could choose to run the service, or it might partner with others at any of a number of points. In the long term, competition among service providers should appear; users should, and would, have the ability to change their service providers. What's important to the success of the system is your access to the server, not who gets you there. Of course, the transparency of the bundled connectivity software would give the vendor of the initial service quite an advantage, since there's always hesitancy to changing something that works. There could be a nice little business here (but maybe not for us); at worst, we should be able to break even.
- Aren't there lots of security and privacy issues inherent in this system? Yes, there are; some technical and some social. These issues have to be gotten right, or the system will not be trusted, and will fail.
- Can non-Family customers — businesses as well as individuals — get into the Registry? Sure. It would probably be in our interest to let individuals and non-commercial organizations join for free; we might charge businesses a fee, since they would presumably be joining for commercial benefit.
A final thing to note about the scenario is that it incorporates, either implicitly or explicitly, a number of ideas that have been advocated within ATG for some time. This, of course, is not a bug but a feature. The value of this proposal lies in tying these and other ideas together in a different and unified way, and in describing an infrastructure that makes the overall set of capabilities possible within a world of open Internet standards. That infrastructure is MCML.
8. Footnotes
- Building Global Knowledge Webs: Knowledge Representation for the Web. Panel Session at the Fourth International Conference on the World Wide Web, Boston, December 11-14, 1995. (https://www.w3.org/pub/Conferences/WWW4/Panels/krp) back to text
- E.g., Weibel, S., Godby, J., & Miller, E. OCLC/NCSA Metadata Workshop Report, 1995. (https://www.oclc.org:5046/conferences/metadata/dublin_core_report.html) back to text
- References here and elsewhere to Lycos apply equally well to other term-based search engines. back to text
- Truth in advertising: The initial search carried out by V-Twin pointed to pages on the real ATG web site, which had not been augmented with the MCML markup. To simulate how V-Twin would have handled the marked-up site, I did the search on the real ATG site, saved the results in a file, and mapped the URLs from the real ATG site to the corresponding locations on the demo site. The CGI script then loaded the "results" of V-Twin's search from this file, instead of doing a live search. This has no effect on the design or operation of the search strategy, of course. back to text
- either through an 800 number or a local number based on the user's address information. It's critical that the TCP-based networking that presumably underlies all this be completely transparent to the user; nothing more should be required than plugging in a phone line and, maybe, selecting which of several phone numbers should be used for making the connection. back to text
- We can consider cross-platform aspects of all this later; for now, let's assume that this is Mac-only. back to text