
(really) Interactive TV: A proto-proposal
In retrospect...
Back in the latter days of Apple's Advanced Technology Group — Not Dead Yet, but not all that well — Don Norman, our VP at the time, encouraged us all to think deeply about potential new directions for our research, and for Apple products. There was a product group in Apple working on interactive TV (some of the prototypes still turn up on eBay from time to time), Don was Apple's rep on an ITV industry standards group, and I had always been interested in pushing some of the aspects of computing into the world of television. A few frenzied days of writing and Photoshopping produced this. I have a vague memory that Don presented some of this at one of those standards meetings, and that, for several weeks afterwards, the trades were filled with corporate visionaries telling stories about interactive extensions of sports broadcasts. Probably just simultaneous discovery, or ego-driven memory creation.
Well, we're still a long way from getting this kind of interactivity on our televisions: technolgical issues, standards, business issues, and social/interactional matters all stand in the way. I'll cop to getting caught up in technological enthusiasm while writing this, although I'm happy to argue that the paper was meant to make the case for "lean forward" interactive capabilities, and that later work would find the proper balance between these ideas and the more typical "lean back" modes of watching TV. In any case, I think we're now seeing some of these ideas being handled by adapting or re-purposing present-day technologies — do you, or your kids, watch TV with a laptop nearby, showing content and providing an interactive experience related to what you're watching? Similarly, the web support for live sports events is not unlike what you'll see in this paper. Computers and television are continuing to merge, and I don't think this story has ended yet.
1. Reflections on the Internet, media, and intelligence.
It's possible to look at what's happening with the Internet, and the World-Wide Web in particular, as moving us toward a model of documents that know something about their content. From this perspective, documents are no longer just passive streams of characters, but authored objects that contain pointers from meaningful document components to other documents or services. This model works great as long as someone is willing to mark up the document, and as long as the document will be read in an application sensitive to the mark-up. Unfortunately, you can't count on these requirements always being met - most of the applications we commonly use can't be and won't be web browsers, and many if not most of the documents we work with are too transitory to justify taking the time to author them into a web-ready form. This breakdown of the HTML model coincides with our work on structure detection (Miller & Bonura, this volume; Nardi, Miller, & Wright, 1998), in which we use textual recognizers to find meaningful components, like e-mail addresses, phone numbers, and URLs, in users' documents and then provide easy access to actions that make sense for those components (e.g., if an e-mail address is found, let me send an e-mail message to that address).
Through our work on Apple Data Detectors, we pursued the obvious vector of this idea: Get the technology solid; understand how to insure its broad acceptance; and ultimately enable cooperating communities of people to build and share recognizers for many different purposes. But there is another question that runs along a different vector: Can we apply this technique to other forms of media, for other markets and other tasks? Text is not going away, but other media are at least as prominent, and may offer opportunities that equal or even go beyond what we can do with text on the desktop.
Consider video - television, that is. The significance of television in modern society does not have to be commented upon. However, it is currently an isolated medium; it has not been possible to connect television into a rich and broadly-based information/media environment. Thus, most current (JRM note: remember, this was written in 1995) models of interactive television (ITV) are quite impoverished; most proposed systems are focusing on video-on-demand, games, and home shopping, even though the people taking part in the early ITV trials are reporting only limited interest in those services. Our speculation here is that we could do something very powerful and valuable with a more broadly-defined notion of television, and that World-Wide Web and structure detector techniques could be central to the creation of that value.
Specifically, we could apply the HTML / structure detector model to represent the information in many forms of dynamic media, and use this as a basis for broadly-based communication and information services.
The keys to making this work will require the extension of some existing technologies, but little that is beyond the horizon of where we are today. The bulk of the research work would lie in the integration of these existing and extended technologies. In particular, we would need to:
- Generalize HTTP and HTML to provide uniform access to a broad collection of media and services.
- Expand the ability of our existing platforms to explicitly represent the meaning of the objects they are manipulating, and to derive some degree of meaning from the textual depictions of non-textual media.
- Provide a means through which these representations can be delivered to users' systems. Embedding this information in the closed-caption section of the video signal will work in the near term; we can safely expect that other, more direct means will exist in the near future.
Also important would be a parallel body of work on the creation of the business models and infrastructures that would enable these technologies to take root and grow. This is more a matter of marketing and evangelism than inventing dramatically-new technologies.
But, enough theory and generalities. Exactly how all this happens, and what the world we envision looks like, is perhaps best told through a scenario.
2. A scenario.
I'm sitting in my living room, thinking about watching a baseball game. I'm sitting in front of a large-screen video system built around a set-top box and its accompanying high-bandwidth communications-TV-data connection, which is driven by an augmented "TV remote control".
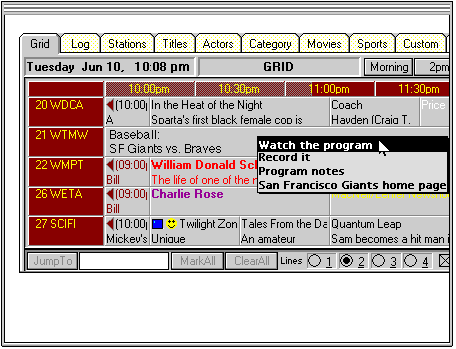
Figure 1. I find the Giants game in my current TV listings, and ask to watch it by selecting the menu item associated with the game's entry.
I'm browsing through the TV listings - on-screen, of course, since those listings are always up to date, and they're easier to search - and I see that there's a Giants game on. I use the remote control to click on the game's entry and get a menu of options related to the broadcast. Selecting Watch the program puts the TV listings away and switches me to the game. (Figure 1)
What's really going on: This application may simply be a web browser, showing the current TV schedule held on a web site. The image shown here is based on ETV (https://www.microserve.net/~tvhost/); web-based and application-based "TV Guides" have recently been proliferating. Now, assume that there is some degree of representation associated with the HTML that encodes the TV schedule, perhaps XML based, providing the interpretation of this information as a TV schedule. The actions in the menu are then derived from two sources: the interpretation of the annotated HTML ("what kinds of actions are possible with a TV schedule?") and the recognition of terms like "S F Giants" - a term of personal significance to me - via a Data Detector looking at the content of these program entries.
Clicking on Watch the program activates a new variety of URL, perhaps tv://kron/ch04/2200/2359. The helper application for this URL activates the TV tuner part of the system and switches me to the appropriate channel. In the case of programs airing in the future, comparable URLs and actions could set up my VCR to record it (perhaps reminding me at an appropriate time to be sure to load the VCR with a fresh tape), or ask the system to remind me about the program a few minutes before it comes on.
My system is now configured into a form designed for watching sports broadcasts (Figure 2). This display contains a number of other related windows, which are significant if not essential parts of my sports viewing. I get an an active scoreboard of today's games, and note that the A's are down by five runs. What else is new.... I open up the Scoreboard Agent (not shown) and ask it to keep track of this game - it should let me know if the A's get within a run.
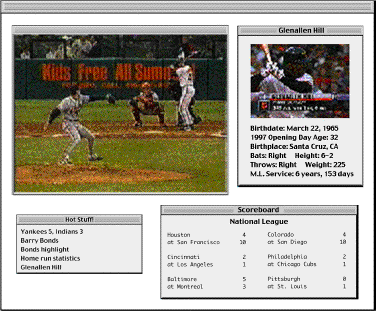
My display also includes a "color commentary" window (to the right of the TV window) for information related to the game. Its standard behavior is to display information about the current batter or other relevant players, but I can always request other kinds of information. Here, I'm curious about the current batting average of the next batter, so I press a button on the system's remote control and say "Show me Glenallen Hill" into the embedded microphone; a picture and short bio of Hill appears in the color window.
The HotStuff! window gives me a rolling list of references to things that are discussed during the course of the game - players, scores from other games, comments about good plays from recent games, and so on. Clicking on these will bring them into the color window or launch another display.
What's really going on: As players come up to bat, their names are captured from the closed-caption play-by-play coverage (via Data Detectors and perhaps some limited natural language parsing) . Pictures and other information about the player are then retrieved from the broadcaster's archives. Note that items can also be added to the HotStuff! list by the broadcaster. Clicking on something in HotStuff! overrides the content of the "color commentary" window, and displays content appropriate to the user's request. Speech actions are handled by capturing and digitizing the speech within the remote control, and sending the result to the set-top box, via an IR link, for recognition and handling.
Regarding the Scoreboard Agent: The scoreboard imagined here is equivalent to those available on many present-day sports web sites. Adding a notification process that watched specific games for specific conditions would be relatively easy.
Barry Bonds is up, and, between pitches, the broadcaster mentions the home run he hit the previous night. The reference to this play shows up in HotStuff!; I retrieve the video of it and save it on my home server. Some of the fans collect and trade these clips much like trading baseball cards. I find the ESPN logo to be a little annoying, but not much more so than the logos on baseball cards. Every so often, just for fun, I splice some of these clips together into my own "highlight video". (Figure 3)
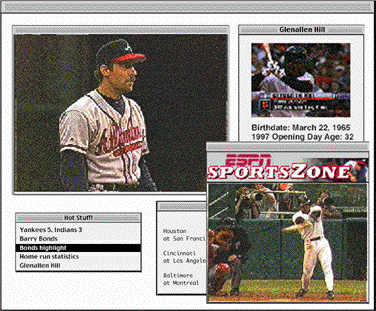
What's really going on: The broadcaster downloaded a URL for the replay video into HotStuff!via the closed-caption channel. Note the mix of free content and advertising: ESPN pays Major League Baseball for the rights to the video clips, and then gives them away to viewers as advertising for other ESPN stuff.
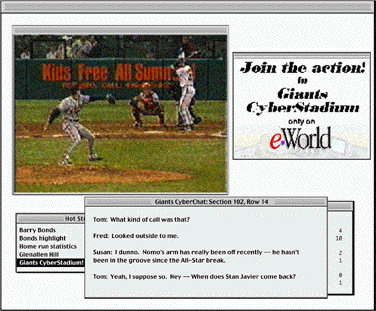
Unfortunately, this is not the Giants' day - their batting is off, and they're down by two runs. Just then, an ad for the Giants CyberStadium chat room on eWorld comes onto the color-commentary window. (These ads are a little annoying, but they're relatively infrequent, and, again, I guess it's the price I have to pay for the information that's usually there.) It might be fun to talk to some people about the game, so I click on the CyberStadium entry in HotStuff! and join up with a bunch of other people around the country who are watching the same broadcast.
I check into my usual "seating area" - hardcore Giants fans only, thank you - and note that Fred, Susan, and Tom are there as usual. (These are people I know through previous broadcasts; I've met Fred in person, and Susan and I are going to go to a game the next time the Dodgers are in town.) We share a few nasty comments about the lack of base hits, and settle into the game. Right now, all the "chatting" has to be done via keyboards, but the next upgrade coming from my local network provider will support full-duplex voice communication, so we can talk to each other. (Figure 4)
What's really going on: As before, the URL for the chat room is downloaded via the closed-caption channel, captured, and added to HotStuff!, from where I can launch this eWorld service.
While we're talking, Bonds comes to the plate and strikes out. Great. It seems like he's been doing that a lot lately, especially against right-handed batters. Susan says she remembers a game earlier this year against the Dodgers when he struck out three times. None of us believe her, so I decide to check the library. I bring up the SportsQuery service - a commercial service on the net, to which I have a shortcut in my interface - and look for games in the last six weeks between the Giants and Dodgers in which Bonds struck out three times. A few seconds later, SportsQuery returns with several probable matches: newspaper articles from the Examiner and the LA Times, and a video clip of Bonds in the game from the archives of one of the San Francisco TV stations. The Examiner article is the cheapest to retrieve - 15 cents, billed to my monthly network account - and, sure enough, Susan was right. The hot dogs at the Dodgers game next month are on me.
As it happens, I was able to follow a few links from the Examiner article to an offshore video server run by a former minor-league player from the Dominican Republic, and I found the same video clip SportsQuery found (although not quite as clear). I sent the clip to Susan by dragging its entry in the SportsQuery window to her name in the chat window. I use this service a couple of times a week, and I'm going to try the (wireless) Newton version the next time I go to a game. I also found a pointer to a scheduled post-game radio interview with Dusty Baker, which I asked to have recorded so I can listen to it later.
What's really going on: Imagining the exact interface for the information query will be left as an exercise for the reader. But something fairly simple should do. The real work lies in how SportsQuery handles the query, since the information I want might exist on any number of physical information servers around the net. It might make sense to use one server to find the dates of all the games between the Giants and the Dodgers in the last six months, and then scan news sources somewhere else for stories from the day after each of those games. There are lots of issues and opportunities for information retrieval and planning here; in particular, some representation of meta-information about the content of the relevant web sites, such as XML, would be essential.
More chatting amongst the four of us, as well as a couple of others who have joined us in the "stadium". The game is going nowhere fast, and we're more into our discussion about the game and the Giants' recent troubles than we are about the game itself. But, what's this: my Scoreboard Agent has reported that the A's have, in fact, narrowed the gap and are threatening to take the lead in their game. I'm more eclectic in my interests than are my friends, so I tell them I'm going to check out the A's game; I'll probably be back later. I accept the Scoreboard Agent's offer to take me to the A's game, which it does by moving me to a new display built around the A's and this particular game.
Much of this new display is the same as the interface for the Giants game, but there are a few unique features here, like free access to their video archives. (The Giants charge for access to their archives, but the A's found that any money they lost from archive access was more than made up for by better television ratings for their games, more revenue from their interactive ads - T shirt sales are up 20% - and greater ticket sales. Of course, the argument continues; the marketing groups for both teams both insist their analysis is the right one.) Sure enough, the bases are loaded, and Jose Canseco is coming up. There might be some hope, after all....
3. Summary.
Hopefully, this scenario has been meaningful, even if the reader happens not to be a baseball fan. It should at least be clear that this is only one instance of a large number of possible domains where significant value could come from the integration of different media; one can imagine comparable environments for congressional hearings or criminal trials, in which live testimony is supported by and interleaved with access to court records, past testimony, evidence, and the like. Similar support could be given to educational lectures, especially those specifically prepared in electronic form for repeated presentation. (Repeated presentation would ease the amortization of the cost of "indexing" the video with appropriate references to other source materials.)
The main point of the scenario, of course, is to convey a picture of what an integrated media/communications system might be like and how it might be used. Commentaries along the way have identified some of the relevant implementation issues; as noted earlier, such a system would require broader HTTP-like protocols and equivalents to HTML helper applications, and a richer representational basis for describing the objects being accessed by the system.
Questions about the details of the scenario, and this whole approach to TV and the Internet, abound. Some are purely technological, such as the availability of appropriate TV equipment and high-speed Internet bandwidth to the home. We can probably assume that these will be solved in a few years by the application of other market forces; more problematic are issues surrounding the usage patterns and business models implicit in this vision. In particular:
- If we build it, will they come? This was true when this paper was first written, and it's still true. There is a leap of faith inherent in idea of television-internet integration: That consumers want to have their TV-viewing experience transformed into something less passive than it is today. The validity of this assumption is less than clear: we shouldn't assume that millions of people will change their habits simply because some new technologies have become available. It will be important to develop this model iteratively, experimenting with different approaches (e.g., more or less automaticity in accessing information), customer bases (are young viewers more open to this approach?), and domains (what domains are particularly good matches to this technology merger?) in search of system/interaction designs that deliver significant value and also match the desires, needs, and interests of consumers.
Is there a business model to justify annotation? Can we convince broadcasters and other content providers to provide this sort of live annotation of their broadcasts? I'm optimistic: closed-captioning services are already being provided for many TV broadcasts, so the human and technological infrastructure for providing this sort of interactive content is already in place. In addition, annotations like these are already being produced for Intel's InterCast system, and other Internet/TV hybrids are also exploring this territory. In addition, some annotations could be built into the system; for instance, displaying the CyberStadium ad could automatically insert an appropriate URL into the closed-caption stream. Others could be identified ahead of time and set up to be easily referenced, such as URLs pointing to the video clips of recent good plays by the teams playing today.
Exactly where these annotations come from is another matter. In the long term, the success of this model implies that the creation and broadcast of these annotations is just another part of the content creation process by the production company, and is funded and managed as an inherent part of the content production. How we get to that position is another question. Creating this interactive content is a new skill, in terms of both technology and expertise; what is needed are "webcasters" who attend events, produce the interactive content, and merge it into the broadcast content for distribution to their customers. ITV companies might take on the development of such groups themselves to demonstrate the value of the approach and to insure that the consumers who purchase their equipment and services get something for their money. Over time, as acceptance of and demand for this kind of media grows, the funding and management of these groups might shift from the ITV companies to the broadcast or production companies, in the interests of greater control over the creation of the interactive content and more explicit connections into other content owned or produced by the broadcast or production companies. Clearly, the production of this content would be best done in collaboration with the broadcasters and/or production companies, but it's interesting to think about whether the creation and distribution of the interactive content could be done independently of them, using the Internet as a distribution medium that runs in parallel to the broadcast content.
Beyond this, I'm hopeful that the same reasoning would apply to interactive content as already applies to the creation of good web pages: better annotations would make for a better user experience, and people would vote with their feet - their mice? - by going to those programs that are best tied into the rest of the information and communications world. Success here could be marked by hearing someone say "I don't want to watch that - all you can do is watch it."
Television-Internet integration is one of those ideas that is easy to imagine becoming a reality - the steady flow of science fiction movies depicting such systems have seen to that. What these depictions hide from us, of course, are the technological and social roadblocks along the way to this idealized future, and the inevitable collection of flawed and failed - albeit well-intentioned - attempts to implement specific systems and build successful businesses around them. There's little theory we can rely on here to help us design a winning approach; moving forward instead calls for a solid layer of experimentation, iteration, and careful listening laid upon a sound technological and business foundation. And not a little luck....
References
Miller, J. R., & Bonura, T. (1998). From documents to objects: An overview of LiveDoc. SIGCHI Bulletin, April 1998.
Nardi, B. A., Miller, J. R., & Wright, D. J. (1998). Collaborative, programmable intelligent agents. Communications of the ACM, in press.
About the Author
Jim Miller was the program manager for Intelligent Systems in Apple's Advanced Technology Group. He is currently exploring consumer applications of Internet technology as part of Miramontes Interactive.
Author's Address
Jim Miller
Miramontes Interactive
14889 Jadestone Drive
Sherman Oaks, CA 91403
email: jmiller@miramontes.com
Tel: +1-650-949-3043