
IEEE Internet Computing, July/August
2006:
Getting conceptual about interface design
In past columns, I’ve had a lot to say about the importance of tasks in user interface design and the need to focus on how users think about their tasks when they’re using an application. It’s time to get more detailed about what this means, and consider how designers can use these general considerations as the foundation for designs and interfaces.
Perhaps the easiest job an interface designer can have is building an interface for a single, highly-focused task, one in which users follow a fixed sequence of actions. Think of the multiple-panel “wizards” that are commonly used to install software: a succession of panels lead us through the process, answering a question or two on each, until the task is completed. Some of the questions might introduce a bit of complexity or branching, but, on the whole, the task is so constrained that leading the user by the hand through a series of questions works fine.
Unfortunately, it’s much more typical that an application must support many tasks of many different kinds. As a result, its users are faced with questions like: How do I know what I can do with the application? How do I do those things that the application supports? How do I know if an action did what I wanted it to do? If it didn’t, how can I correct my error?
Let’s look at these questions from the perspective of a very simple task — managing a desktop file system. To reminisce a bit, we can look back to the early days of interactive computing, when the command-line interfaces of MS-DOS, Unix, and the like were the norm. Users had a collection of textual commands like rename or mv, and they spent a lot of time typing the commands and the names of the files they wanted to manipulate. These interfaces worked, but they posed severe usability barriers: lots of commands, often with names that were hard to remember, lots of typing (and thus lots of opportunities for typing errors), and very little information about the state of the file system: still more commands were needed to find out where you were in the file hierarchy or to confirm that your actions had achieved their desired result.
All of this changed significantly for the better with the development of graphical interfaces of the sort we’re all now used to with Macintosh, Windows, and similar systems. These interfaces give us a visual depiction of the machine’s file system, in which files and directories are depicted as real-world objects on the screen, and our actions in the file system are replaced by actions on the icons representing these objects. Using the mouse to drag an object from one folder to another moves that object from one directory to another. With some exceptions, which I’ll discuss, this style of interface is a big improvement over the command-line approach: there are no commands to remember, nothing to type, and an action’s success or failure is immediately apparent in the on-screen depiction of the folders’ contents.
Conceptual models
What’s significant about this interface is how it takes advantage of the analogy between the computer’s concept of a file system and the real-world notion of files and folders. Another way to refer to this visualized analogy between the real file system and its graphical depiction in the interface is as a conceptual model — a way for the interface designer to explain to its users the application’s capabilities.
One of the things we’ve learned in the HCI world is that people will always come up with some sort of conceptual model to guide their interaction with an application. The challenge for an interface designer is not whether or not to have a conceptual model, but to identify an appropriate conceptual model for the application and make sure that it comes across well in the interface. Conceptual models are relevant to all kinds of interfaces, not just graphical ones — after all, people thought about file systems as a hierarchy of containers long before there were graphical interfaces. Typing a reference to some part of this container hierarchy as a string of terms separated by special characters — C:\WINDOWS\SYSTEM32\SCROBJ.DLL — is arguably not the best user interface to a file system, but, like it or not, it’s the technique that’s available to a command-line interface, and it plays a key role in how people manage file systems with these interfaces.
In any case, the richness of an application’s conceptual model and the way in which that model is depicted in the application’s interface has a lot to do with the application’s user experience, how easy (or hard) the application will be to use, and how much of the application’s power the user will be able to exploit. The more your application supports open-ended interaction — something other than a simple, predetermined set of tasks — the more the quality of your application’s conceptual model and its depiction in its interface will define your users’ success.
What does a conceptual model do for its users?
A good conceptual model offers its application users ways to think about the capabilities it’s offering to them, often via analogy to real-world objects and actions. The real-world analogy is important: it’s easier to think about concrete items than abstract relationships, and people often think about an application’s operation in terms of operating on concrete objects (“I took the file out of this directory and put it into that one.”). Further, the properties and behavior of the real-world objects should correspond to those of the objects in the interface: if I move a folder — real or virtual — to a new location, whatever was inside the folder at the beginning of the process is still inside it at the end. A good conceptual model also offers users a clear way to think about the application’s internal state: what’s being manipulated, how those things are related to each other, and the cumulative effects of the user’s actions on them.
A conceptual model gives users a way to make reasonable predictions about the effects of their actions, based on the analogies that comprise the model. This is one reason why keeping users aware of the application’s internal state is important: it’s how they determine whether the predictions based on that model were or were not correct, and helps them learn what they can and can’t do. Finally, a good conceptual model provides a clear foundation for the development of an interface around it.
It’s also important to note what a conceptual model is not. First, a conceptual model isn’t a restatement of the system architecture. The fact that we’ve talked a lot about objects and actions makes the design of conceptual models sound rather object-oriented, and it often is. But an application’s conceptual model is rarely the same as the system architecture: the way you organize your application’s code to create an application that is modular, efficient, and easy to maintain is likely to have little to do with how people think about the tasks supported by that application. Second, a conceptual model need not reflect what’s really happening inside the application — its only job is to guide users’ thinking about what’s going on. File systems don’t physically move a file to a new position on the disk when that file’s location in the file hierarchy is changed — they just change an entry in the directory structure. But, from a user perspective, this technical inaccuracy is irrelevant — what’s important is that the analogy of files and folders helps the users understand the domain and the application, and lets them get their work done.
Having said all this, it’s important to recognize that conceptual models are rarely perfect. Sometimes the analogy underlining a model breaks down: for instance, the spatial positions of document icons in the depiction of a folder generally don’t correspond to anything meaningful in the file system. Nevertheless, it’s quite common for new users of a graphical file browser to be very concerned about the exact location of the icons, and it takes some effort to convince them that “the computer doesn’t care.” Similarly, there’s nothing about real-world files and folders that has anything to do with the CTRL key on a computer keyboard, much less how holding the CTRL key down while dragging a document icon to a new location copies the document instead of moving it. In addition, sometimes a model bumps up against limitations of the task it’s supporting: selecting file icons with a mouse isn’t a great way to work with a million files, or a collection of files spread over the Internet. Conflicts like these are inevitable when you’re doing design in the real world: as always, your top-level goal as a designer is to understand your users and their tasks, and optimize your design for them as best as you can. But design in general (and perhaps especially interface design) always has this sense of optimization, so we’re really no worse off than we would be otherwise. These issues don’t reduce the importance of a good conceptual model for an application; they just serve as one more factor in the design process.
Applying conceptual models
So how can you take advantage of conceptual models when you’re designing your application’s interface? First, base the model on how your users think about the application’s domain. This should be based on a task-oriented view of the domain, and you should be careful to identify the objects and actions that characterize the domain. Talk to your users about their tasks and listen carefully: see how they frame their discussion in terms of objects and actions. They’re likely to use real-world analogies as they talk, and, the more these objects and actions are things in (or that can correspond to) the real world, the better.
Then, design the interface, from the beginning, around that model and the objects and actions that comprise it. As you address the model’s objects, you’ll want to depict them in some way that your users will easily recognize in the finished interface. This doesn’t have to mean icons and purely graphical depictions, but it does mean that you’ll need to put the presentations of the model’s objects and actions, whatever they are, at the center of the design. Terminology choices here are important, in that they help convey the analogy between the interface and the real world. The concreteness of the term “folder” makes it work very nicely for file management: folders clearly correspond to things in the users’ experience, and they offer guidance to actions and the creation of predictions about actions.
One of the harsh truths of interface design is that you don’t have complete freedom in creating your design, even if you’re keeping the needs of your users as your top priority. Your application is going to have to live alongside many others, and it will need to fit in with them. If you use standard interface techniques in a nonstandard way, problems are likely to occur, as your users discover that all the things they’ve learned in other applications and other Web sites don’t apply to yours. Of course, as a practical matter, most applications are built with toolkits provided with the platforms on which they run, and most Web sites are built primarily with HTML. Reliance on these toolkits helps with this problem of fitting in; it’s usually rather hard (but, sadly, not impossible) to use toolkits to produce interfaces that behave in ways other than they “should.” But a tension still exists between doing things the way that “everybody else” does them and moving the field forward by trying new things. On the Web, it’s easy to find novel interaction techniques built in Flash, and other new techniques are growing out of the greater interactivity offered by “Web 2.0” technologies such as Ajax. Sometimes these are great new ideas and sometimes they’re not, but the interface design world is pretty Darwinian: good ideas are shared and adopted, and lesser ideas fade away. You’ll need to find the right trade-off between old and new and base your design on what’s most important for your users.
A more complete example: Playing music
Let’s look at a more complicated task — playing music — and consider how different user tasks suggest different conceptual models, and, thus, different interfaces. The first example here is Apple’s iTunes (Figure 1). The interface’s job here is to help people find and play music in their digital music library, and iTunes does a very nice job of it. In terms of screen real estate, the interface’s focus is almost completely on the task of finding the music to be played, and it does so by focusing on the main components of the iTunes conceptual model: the music’s artists, albums, and song titles. The iTunes conceptual model portrays this information as a tree structure, in which artists have albums, and albums contain songs. The design challenge is then figuring out how to present and offer control over what could be a very large tree structure (in my case, about 10,000 songs). It does this by presenting the artist, album, and song information in different panels of the interface and making each one a control for those that are conceptually below it: selecting an artist updates the album and song panels to show only the information for that artist, and selecting an album updates the song panel to show only the songs in that album. Other bits of information, like genre, publication date, and track number, can be added or removed from this display, depending on users’ preferences or specific task requirements (such as finding all the songs by an artist recorded between 2004 and 2006).
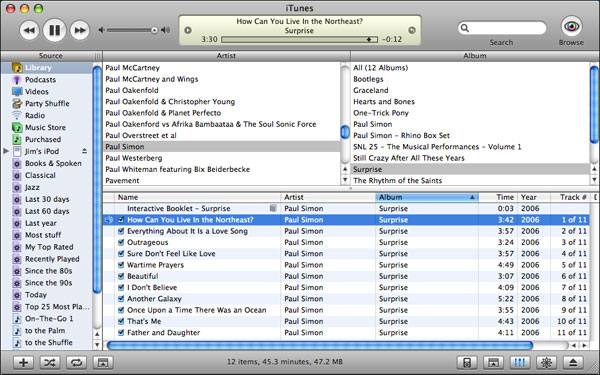
The top of the display contains the controls for playing those songs that are currently in the songs panel. The main controls are designed to match the familiar play/pause/next track/previous track controls of tape recorders and DVD players, as are the “shuffle” and “loop” buttons at the bottom of the display. Other controls draw on users’ experience with the general computer environment on which iTunes runs: the volume control and search box are the same controls that are used elsewhere on the Macintosh, as are the list boxes containing textual information. General interaction rules from the platform also apply here: just as double-clicking an application icon on the desktop launches that application, double-clicking a song title plays the song.
iTunes also does a good job of making the application’s internal state visible to its users. The songs to be played appear in the main song panel, in the order in which they will be played. In this panel, the song currently being played is marked with a small “loudspeaker” icon in the song panel, and the central song display at the top of the interface shows a rotating textual display of the names of that song’s artist, album, and the song itself. This display also contains a graphical view of the song’s duration, and an indicator of where we are in the playing of the song (which can be dragged forward or backward to change the part of the song being played).
Like any interface designed for a complex domain, there are places in iTunes where the complexity of the domain, the structure of the conceptual model underlying the interface, and the practicalities of the interface itself lead to trade-offs. For instance, compilations — albums made up of songs by several different artists, such as movie soundtracks — violate the strict artist–album–song hierarchy that’s at the heart of the iTunes conceptual model. A compilation album can’t be represented as being “by” a particular artist, and so it can’t be represented in the artist panel. It can only be found by selecting “all artists” in the artist panel and then searching for the album title in the album panel. Once that album is located, its songs are presented in the songs panel, with each artist’s name appearing by their songs’ titles. However, when an album by a single artist is playing (as in Figure 1), the album and artist information in the song panel is of course always the same, and consequently, much of the panel is taken up with redundant information. This trade-off doesn’t doom iTunes; it’s simply a reflection that even a well-designed interface, based on a clear and easily understandable conceptual model, will have places where it bumps up against the real world, and where the designers have to make a judgment call based on their understanding of their users and their tasks.
Example 2: CD Spin Doctor
Just so we don’t fall into the trap of thinking that there’s only one way to do a task like playing music, let’s look at a another application. CD Spin Doctor (Figure 2) takes a completely different approach to music than does iTunes.

CD Spin Doctor doesn’t concern itself with finding a particular piece of music in a large library; rather, it’s designed to accept a single large music file, such as might correspond to a complete album. Figure 2 shows the application’s view of what’s depicted in Figure 1’s view of iTunes: we’re about three and a half minutes into the album. But what we’re seeing here, and what we can do, is nothing like what we see and can do in iTunes. CD Spin Doctor generates an oscilloscope-like visualization of the music file, and lets us put a play head — the black triangle next to the dotted line — anywhere in the file and start playing it at that point. There is nothing here about artists or albums or even song names; we’re just playing a big, long file of music.
The trick, of course, is that CD Spin Doctor is designed for a completely different task than iTunes. CD Spin Doctor isn’t mean to play a collection of tracks, but to allow its users to manipulate a music file that is a continuous recording of a sequence of tracks, such as a digitized recording of a vinyl record. As a result, CD Spin Doctor is built on a completely different conceptual model — that of a long piece of music, much like a piece of audio tape. The auditory information received from manipulating the play head can be used, along with the oscilloscope-like display, to find the places where track breaks occur (the “flatline” space just to the right of the play head in Figure 2) and so identify the beginning and ending points of the songs in the file. Tracks can then be identified by marking these positions with menu commands or by dragging the mouse over a section of the file’s waveform. In addition, other application commands are designed to support track creation, such as making one track start exactly where the previous track ended. Ultimately, the user can use CD Spin Doctor to mark the positions of all the tracks in the file and have the application create new files corresponding to each identified track, which users can then enter into their music libraries to play with iTunes or some other comparable application. CD Spin Doctor would be a terrible substitute for iTunes; the good news is it’s not meant to be one. Even though they’re both generally in the music domain, the two applications’ tasks are completely different, as are their conceptual models and, thus, their interfaces.
I hope this has given you some insights into the importance of conceptual models for interface design. Once again, your users are going to come up with some conceptual model to guide their work with your applications. Because this isn’t something you have much of a choice about, it’s in your interest to find a conceptual model that matches your users’ needs and build your interface around it. Your users will be happier and more productive, and your application will be much the better for it.
Jim Miller is principal of Miramontes Interactive, an interaction design consultancy. His research interests include Web-based application design, Internet community development, consumer Internet appliances, intelligent interfaces, and usability evaluation methods. Miller received a PhD in psychology from UCLA. He is a member and past chair of SIGCHI, the ACM special interest group on human-computer interaction. Contact him at jmiller@miramontes.com.
For further reading
Don Norman: The Design of Everyday Things (1990, Basic Books). Great insights into the ways people find and use conceptual models to think about everything from doors to computers, and how good design can help get the right models across to them.